|
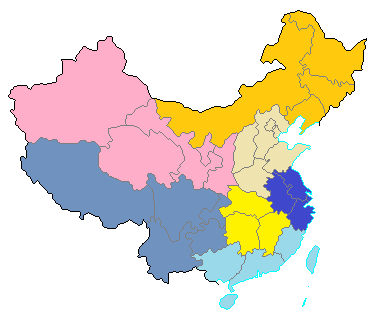
YИҫЙ«уwИФ°ҙТФНщөДҙу·ЦоҗЈ¬·ЦБЛ16оҗЎЈЖдЦРЈ¬Y*КЗЛщУРІ»ДЬҡwИлЗ°БРҶОұ¶БtөДЖдрNоҗРНЈ¬°ьАЁE, G, H, I, J, K*, L, TөИөИЎЈ ҪyУӢ•ә•rПИЦ»УӣқhЧеөДПа»ҘҹoкPҳУұҫЈЁТФНщәҶ·QЎ°қhЧеҹoкPҳУұҫЎұЈ¬ҪoҙујТФміЙБЛТ»Р©Х`•юЎЈТвЛјКЗХfЈ¬ёёПөКЗқhЧеөДЈ¬ҳУұҫКЗПа»ҘҹoкPөДЈ¬јҙИз№ыН¬Т»ҪьЧжөДҳУұҫУР¶аӮҖЈ¬„tЦ»УӢЛгТ»ӮҖЎЈұИИзН¬аlжҒЎўН¬РХ»тјТЧVДЬЯBөҪТ»ЖрУРҪьЧжЈ¬ЗТ17-STRҪY№ы·ЗіЈҪУҪьөДЈ¬ҫНЦ»°ҙТ»ӮҖҳУұҫУӢ”өЈ©ЎЈ ҙу…^·ЦБЛ7ӮҖЈ¬І»КЗ°ҙТ»°гөДҳЛңКЈ¬¶шКЗ°ҙҙЛҲDЈә ЖдЦРЈ¬ИA–|ЈЁҪӯХгңыНоЈ©өДҳУұҫБҝЧоҙуЈ¬ҪY№ыТІ•юПаҢҰұИЭ^ңКҙ_ЎЈЖдЛыҙу…^ПаҢҰҳУұҫБҝРЎТ»Р©Ј¬ө«ЦБЙЩЙП°ЩБЛЎЈ қhЧеПа»ҘҹoкPҳУұҫөДYИҫЙ«уw°ҙөШ…^·ЦҒСЈ¬2014Дк9ФВҪyУӢ ОТПВЦЬЖр°lҒСөЪ¶юЭҶ#ГҝЦЬТ»РХ#ЎЈТФббөДГҝЦЬТ»РХТІИФЕf°ҙТФЙПөДYИҫЙ«уw·ЦоҗЎЈЦ®З°өДГҝЦЬТ»РХ°lҒСЯ^50¶аӮҖ°ЙЈ¬ббҒнТт ‘Т»ӮҖРХКПөДҳУұҫЯ^ЙЩЈЁІ»өҪК®ӮҖЈ¬ЙхЦБЦ»УРБщЖЯӮҖЈ©Ј¬ЛщТФІ»ФЩ°lҒСБЛЈ¬ТФГвУӢ”өЙПөДлSҷCХ`ІоҢҰҙујТФміЙеeХ`УЎПуЎЈУРИЛҪЁЧhОТ°СРХКП°ҙКЎ·ЭҪyУӢЈ¬Я@ӮҖёьІ»ИЭТЧБЛЈЁіэБЛЧоҙуөДҺЧӮҖРХЈ©Ј¬Тт ‘ҳУұҫБҝҫНЯ@ьNьcғәЈ¬¶шЗТТ»І»РЎРДҝЙДЬ•юР№В©ӮҖИЛл[ЛҪБЛЈЁТт ‘УР•r•юУРИЛЦӘөАХlөҪОТЯ@СYңyЯ^БЛЈ¬ҝЙТФУГійҢПФӯ„tІВЈ©ЎЈОТЯ@СYКЗәЬФЪТвұЈЧoл[ЛҪөДЈ¬Из№ыӣ]УРКЪҷаОТ°lҒСЈ¬ОТ•юЦ»°lҒСҝӮөДҪyУӢҪY№ыЈ¬¶шІ»•ю°lҒСӮҖИЛҪY№ыЈЁө«ОТ№Д„оҙујТЧФРР°lҒСҪY№ыЈ¬»тКЪҷаОТ°lҒСЈ©ЎЈДҝЗ°УРЦБЙЩ10ӮҖӘҡБўқhЧеҳУұҫөДРХКПТСҪӣУР40¶аӮҖБЛЈ¬БнНвЙЩ”өГсЧеҙуРХОТТІ•юЧГЗй°lҒСөДЎЈ | 

 ҝъКУҝЁ
ҝъКУҝЁ АЧҙпҝЁ
АЧҙпҝЁ ·ўұнУЪ 2016-1-10 18:08:30
·ўұнУЪ 2016-1-10 18:08:30

 МбЙэҝЁ
МбЙэҝЁ ЦГ¶ҘҝЁ
ЦГ¶ҘҝЁ іБД¬ҝЁ
іБД¬ҝЁ РъПщҝЁ
РъПщҝЁ ұдЙ«ҝЁ
ұдЙ«ҝЁ ЗАЙі·ў
ЗАЙі·ў З§Ҫп¶Ҙ
З§Ҫп¶Ҙ ПФЙнҝЁ
ПФЙнҝЁ /2
/2 
